port(confluent reference)
| Component | Default Port |
|---|---|
| Zookeeper | 2181 |
| Apache Kafka brokers (plain text) | 9092 |
| Schema Registry REST API | 8081 |
| REST Proxy | 8082 |
| Kafka Connect REST API | 8083 |
| Confluent Control Center | 9021 |
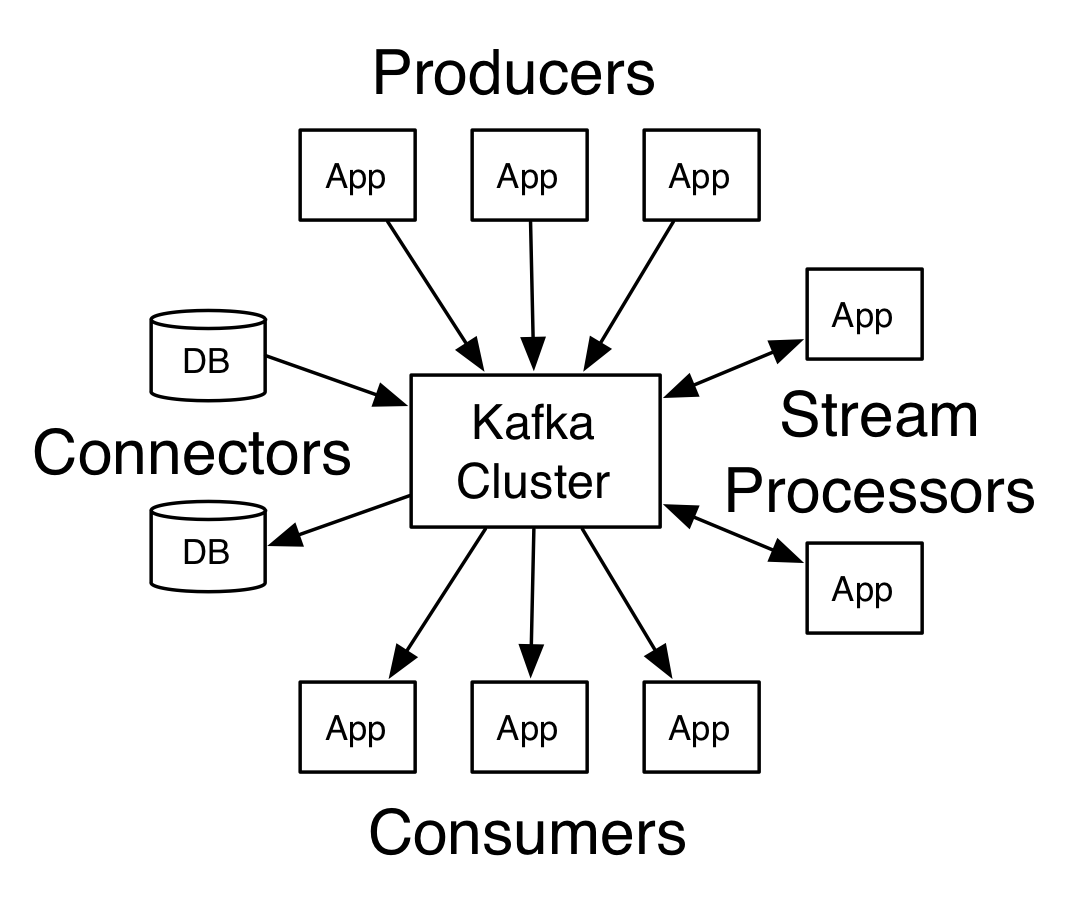
System Architecture

- kafka Producer API: Applications directly producing data (ex: clickstream, logs, IoT).
- Kafka Connect Source API: Applications bridging between a datastore we don’t control and Kafka (ex: CDC, Postgres, MongoDB, Twitter, REST API).
- Kafka Streams API / KSQL: Applications wanting to consume from Kafka and produce back into Kafka, also called stream processing. Use KSQL if you think you can write your real-time job as SQL-like, use Kafka Streams API if you think you’re going to need to write complex logic for your job.
- Kafka Consumer API: Read a stream and perform real-time actions on it (e.g. send email…)
- Kafka Connect Sink API: Read a stream and store it into a target store (ex: Kafka to S3, Kafka to HDFS, Kafka to PostgreSQL, Kafka to MongoDB, etc.)

- Zookeeper : Which is used by Kafka to maintain state between the nodes of the cluster.
- Kafka brokers : The “pipes” in our pipeline, which store and emit data.
- Producers : That insert data into the cluster.
- Consumers : That read data from the cluster.
Creating a topic
1 | bin/kafka-topics.sh \ |
- The
paritionsoptions lets you decide how many brokers you want your data to be split between. Since we set up 3 brokers, we can set this option to 3. - The
replication-factordescribes how many copies of you data you want (in case one of the brokers goes down, you still have your data on the others).
Producer
1 | bin/kafka-console-producer.sh \ |
Consumers
1 | bin/kafka-console-consumer.sh \ |
- The
bootstrap-servercan be any one of the brokers in the cluster. - The
from-beginningoption tells the cluster that you want all the messages that it currently has with it, even messages that we put into it previously.
Try starting another consumer in a different terminal window:
1 | bin/kafka-console-consumer.sh \ |
Kafka as a Messaging System
As with a queue the consumer group allows you to divide up processing over a collection of processes (the members of the consumer group). As with publish-subscribe, Kafka allows you to broadcast messages to multiple consumer groups.
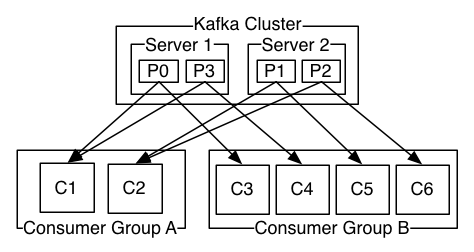
Kafka does it better. By having a notion of parallelism—the partition—within the topics, Kafka is able to provide both ordering guarantees and load balancing over a pool of consumer processes. This is achieved by assigning the partitions in the topic to the consumers in the consumer group so that each partition is consumed by exactly one consumer in the group. By doing this we ensure that the consumer is the only reader of that partition and consumes the data in order. Since there are many partitions this still balances the load over many consumer instances. Note however that there cannot be more consumer instances in a consumer group than partitions.
Each record consists of a key, a value, and a timestamp.
Kafka as a Storage System
Kafka as Stream Processing
source code
源码文件结构
| 目录 | 作用 |
|---|---|
| bin | 存放可直接在Linux或Windows上运行的.sh文件和.bat文件,包含Kafka常用操作以及ZooKeeper便捷脚本 |
| checkstyle | 存放代码规范检查文档 |
| clients | 客户端的实现 |
| config | 存放配置文件 |
| connetct | Kafka Connect工具的实现 |
| core | 核心模块 |
| docs | 官方文档 |
| examples | Kafka生产者消费者简单Demo |
| jmh-benchmarks | 基准测试模块 |
| log4j-appender | 日志模块 |
| streams | Kafka Streams客户端库 |
| tools | 工具类 |
核心模块结构
| 目录 | 作用 |
|---|---|
| admin | 管理模块,操作和管理topic, broker, consumer group, records等 |
| api | 封装调用 |
| client | Producer生产的元数据信息的传递 |
| cluster | 存活的Broker集群、分区、副本以及他们的底层属性和相互关系 |
| common | 异常类、枚举类、格式化类、配置类等 |
| consumer | 旧版本的废弃消费者类 |
| controller | Kafka集群控制中心的选举,分区状态管理,分区副本状态管理,监听ZooKeeper数据变化等 |
| coordinator | GroupCoordinator处理一般组成员资格和偏移量。transaction管理事务 |
| javaapi | 给java调用的生产者、消费者、消息集api |
| log | 管理log,它是消息存储的形式,可对应到磁盘上的一个文件夹 |
| message | 由消息封装而成的一个压缩消息集 |
| metrics | Kafka监控模块 |
| network | 网络管理模块,对客户端连接的处理 |
| producer | 旧版本的废弃生产者类 |
| security | 权限管理 |
| serializer | 消息序列化与反序列化处理 |
| server | 服务器端的实现 |
| tools | 各种控制台工具的实现 |
| utils | 工具类 |
| zk | 提供与ZooKeeper交互的管理方法和在管道之上的更高级别的Kafka特定操作 |
| zookeeper | 一个促进管道传输请求的ZooKeeper客户端 |
主题分区
- 调整分区
1 | kafka-topics --zookeeper localhost:2181 --alter --topic my-topic --partitions 10 |
- 查看分区
1 | kafka-topics --zookeeper localhost:2181 --describe --topic my-topic |
Restful API
AVRO主题相关
一般schema registry 默认端口是8081(有时候避免与flink-jobmanager端口冲突,改为别的端口号 8091)
获取所有主题信息
1
curl -X GET "http://<schema-registry-url>:<port>/subjects"
根据schema id查下相关信息
1
curl -X GET "http://<schema-registry-url>:<port>/schemas/ids/<schema-id>"
获取指定主题key/value相关schema信息
1
GET http://<schema-registry-url>:<port>/subjects/<topic-name>-value/versions/latest
or
1
GET http://<schema-registry-url>:<port>/subjects/<topic-name>-key/versions/latest
参数调优
producer
- batch.size 默认16384
- request.time.ms 默认30000(30秒)
分区和副本
Kafka中的分区(Partition)和副本(Replica)是两个不同的概念,它们在消息传输和存储方面起到不同的作用。
- 分区(Partition)
Kafka的每个Topic都可以被分成多个Partition,每个Partition只会被一个Consumer Group中的一个Consumer消费。在一个分布式系统中,通过将数据分散到多个Partition中,可以使得各个节点负载均衡,并且可以处理更大量级的数据。每个Partition内部维护了一个递增的offset(偏移量),通过offset来标识Consumer在该Partition中已经消费的消息位置。
- 副本(Replica)
Kafka中的副本是指每个Partition的备份,一个Partition可以有多个副本,每个副本都保存着完整的数据副本。副本之间有一个Leader-Follower的关系,其中一个副本作为Leader,其他副本作为Follower。客户端只能向Leader发送读写请求,而Follower只用于备份和同步数据,不能直接处理客户端请求。当Leader出现故障时,Kafka会自动将Follower升级为新的Leader,保证服务的可用性。
总结:分区实现了数据的水平切分和负载均衡,而副本则提供了数据的冗余备份和高可用性,确保数据安全和业务连续性。在实际应用中,需要根据具体的业务需求和技术规划来设置分区和副本的数量,以提高Kafka服务的可靠性和性能。
消费者
消费sasl_plaintext scram-sha-256认证的主题
1
kafka-console-consumer.sh --bootstrap-server your_kafka_bootstrap_servers --topic your_topic --group your_consumer_group --consumer.config client-sasl.properties --from-beginning
其中client-sasl.properties信息
1
2
3security.protocol=SASL_PLAINTEXT
sasl.mechanism=SCRAM-SHA-256
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="your_username" password="your_password";
消费者组
查询消费者组的偏移量
1
kafka-consumer-groups.sh --bootstrap-server <bootstrap-server> --group <consumer-group> --describe
指定消费者组的偏移量
1
kafka-consumer-groups.sh --bootstrap-server <bootstrap-server> --group <consumer-group> --topic <topic> --reset-offsets --to-offset <new-offset> --execute
指定消费组偏移量到最早
1
kafka-consumer-groups.sh --bootstrap-server <bootstrap-server> --group <consumer-group> --reset-offsets --to-earliest --execute --topic your_topic
主题
使为特定主题(topic)配置数据的保留时间。
1
./kafka-configs.sh --bootstrap-server <KAFKA_BROKER_ADDRESS> --alter --entity-type topics --entity-name <TOPIC_NAME> --add-config retention.ms=<RETENTION_TIME_IN_MILLISECONDS>
eg:(设置my-topic主题保留一天数据)
1
./kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-type topics --entity-name my-topic --add-config retention.ms=86400000