容器是一个“单进程”模型
一个“容器”,实际上是一个由 Linux Namespace、Linux Cgroups 和 rootfs 三种技术构建出来的进程的隔离环境
一个正在运行的 Linux 容器,其实可以被“一分为二”地看待:
- 一组联合挂载在 /var/lib/docker/aufs/mnt 上的 rootfs,这一部分我们称为“容器镜像”(Container Image),是容器的静态视图;
- 一个由 Namespace+Cgroups 构成的隔离环境,这一部分我们称为“容器运行时”(Container Runtime),是容器的动态视图。
version
1 | Client Version: v1.30.3 |
define
容器本身没有价值,有价值的是“容器编排”。
Kubernetes is pronounced coo-ber-net-ees, not coo-ber-neats. People also use the shortened version k8s a lot. Please don’t pronounce that one k-eights—it is still coo-ber-net-ees.
Docker is a containerization platform, and Kubernetes is a container orchestrator for container platforms like Docker.
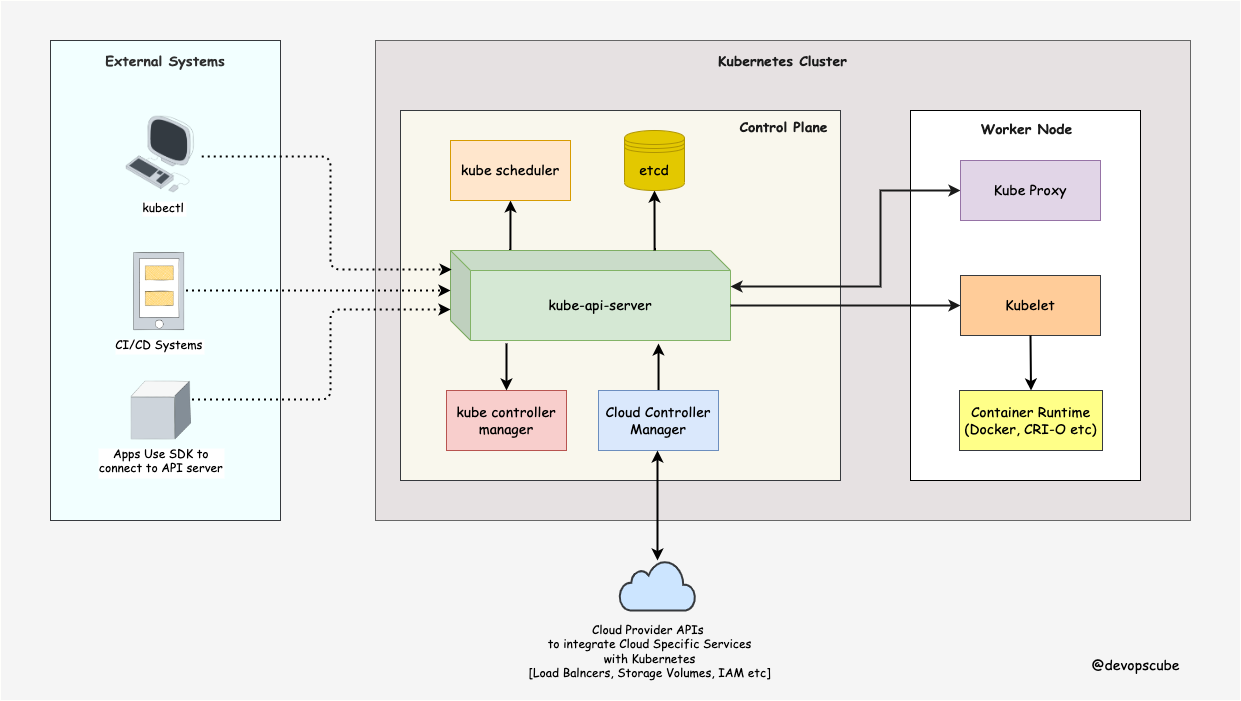
architecture
We can break down the components into three main parts.
- The Control Plane - The Master.
- Nodes - Where pods get scheduled.
- Pods - Holds containers.
kubernetes设计思想“一切皆对象”:应用是 Pod 对象,应用的配置是 ConfigMap 对象,应用要访问的密码则是 Secret 对象。
声明式 API,是 Kubernetes 项目编排能力“赖以生存”的核心所在
dependency
Namespace 做隔离,Cgroups 做限制,rootfs 做文件系统
对 容器项目来说,最核心的原理实际上就是为待创建的用户进程:
- 启用 Linux Namespace 配置;
- 设置指定的 Cgroups 参数;
- 切换进程的根目录(Change Root)。
namespace
Linux 操作系统提供了PID、 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作
1 | PID Namespace:隔离进程 ID。 |
容器帮助用户启动的,还是原来的应用进程,只不过在创建这些进程时,容器为它们加上了各种各样的 Namespace 参数。进程就会觉得自己是各自 PID Namespace 里的第 1 号进程,只能看到各自 Mount Namespace 里挂载的目录和文件,只能访问到各自 Network Namespace 里的网络设备,就仿佛运行在一个个“容器”里面,与世隔绝
在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,最典型的例子就是:时间
Linux Namespace 为 Kubernetes Namespace 提供了底层的隔离能力,Kubernetes Namespace 则是在此基础上进行更高级别的抽象和管理。
mount namesapce
- Mount Namespace 跟其他 Namespace 的使用略有不同的地方:它对容器进程视图的改变,一定是伴随着挂载操作(mount)才能生效。
- Mount Namespace 正是基于对 chroot 的不断改良才被发明出来的,它也是 Linux 操作系统里的第一个 Namespace
cgoups
Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
- Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的
/sys/fs/cgroup路径下 - Linux Cgroups 的设计还是比较易用的,简单粗暴地理解它就是一个子系统目录加上一组资源限制文件的组合
- Cgroups 技术是用来制造约束的主要手段,而Namespace 技术则是用来修改进程视图的主要方法
rootfs
Rootfs(根文件系统) 它只是一个操作系统的所有文件和目录,并不包含内核,最多也就几百兆
容器通过 Mount Namespace 单独挂载其他不同版本的操作系统文件
rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。
挂载在容器根目录上, 为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。
容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核
CRI
Container Runtime Interface 容器运行时接口
kubelet 调用下层容器运行时的执行过程,并不会直接调用 Docker 的 API,而是通过CRI的 gRPC 接口来间接执行
ctr
1 | check ctr images on k8s |
API object
Kubernetes API 对象,由元数据 metadata、规范 spec 和状态 status组成
元数据是用来标识 API 对象的,每个对象都至少有 3 个元数据:namespace,name 和 uid
- 路径
在 Kubernetes 项目中,一个 API 对象在 Etcd 里的完整资源路径,是由:Group(API 组)、Version(API 版本)和 Resource(API 资源类型)三个部分组成的。
1 | # “CronJob”就是这个 API 对象的资源类型(Resource),“batch”就是它的组(Group),v2alpha1 就是它的版本(Version)。 |
Deployment
管理 长期伺服型(long-running)业务
| Aspect | Pod | Deployment |
|---|---|---|
| Definition | The smallest deployable unit, containing one or more containers. | A higher-level abstraction to manage Pods and ReplicaSets. |
| Purpose | Represents a single instance of a running application. | Manages Pods by defining scaling, updates, and desired state. |
| Ephemerality | Ephemeral: Once a Pod dies, it is not automatically replaced. | Resilient: Automatically replaces Pods as needed. |
| Scaling | Requires manual intervention to scale. | Can define a desired number of replicas for automatic scaling. |
| Rolling Updates | No built-in support for rolling updates. | Supports rolling updates and rollbacks for live changes. |
| Use Case | Suitable for testing or single-instance workloads. | Suitable for production workloads requiring scalability and availability. |
pod
Kubernetes 里“最小”的 API 对象是 Pod。Pod 可以等价为一个应用,所以,Pod 可以由多个紧密协作的容器组成
Pod 就是 Kubernetes 世界里的“应用”;而一个应用,可以由多个容器组成
Pod,其实是一组共享了某些资源的容器
凡是调度、网络、存储,以及安全相关的属性,基本上是 Pod 级别的;
凡是跟容器的 Linux Namespace 相关的属性,也一定是 Pod 级别的
凡是 Pod 中的容器要共享宿主机的 Namespace,也一定是 Pod 级别的定义
Pod 里的所有容器,共享的是同一个 Network Namespace,并且可以声明共享同一个 Volume
Pod 可以被看成传统环境里的“机器”、把容器看作是运行在这个“机器”里的“用户程序”
容器,就是未来云计算系统中的进程;容器镜像就是这个系统里的“.exe”安装包
- 每个 Pod 都会被分配一个唯一的 IP 地址。Pod 中的所有容器共享网络空间,包括 IP 地址和端口。Pod 内部的容器可以使用
localhost互相通信。Pod 中的容器与外界通信时,必须分配共享网络资源(例如使用宿主机的端口映射)。 - 可以为一个 Pod 指定多个共享的 Volume。Pod 中的所有容器都可以访问共享的 volume。Volume 也可以用来持久化 Pod 中的存储资源,以防容器重启后文件丢失。
DaemonSet
管理 节点后台支撑型(node-daemon)业务
- 这个 Pod 运行在 Kubernetes 集群里的每一个节点(Node)上;
- 每个节点上只有一个这样的 Pod 实例;
- 当有新的节点加入 Kubernetes 集群后,该 Pod 会自动地在新节点上被创建出来;而当旧节点被删除后,它上面的 Pod 也相应地会被回收掉。
job
管理 批处理型(batch)业务
StatefulSet
管理 有状态应用型(stateful application)业务
StatefulSet 的核心功能,就是通过某种方式记录这些状态,然后在 Pod 被重新创建时,能够为新 Pod 恢复这些状态
拓扑状态
Headless Service
通过 Headless Service 的方式,StatefulSet 为每个 Pod 创建了一个固定并且稳定的 DNS 记录,来作为它的访问入口。
1
<pod-name>.<svc-name>.<namespace>.svc.cluster.local
- 存储状态
Kubernetes 中 PVC 和 PV 的设计,实际上类似于“接口”和“实现”的思想。
Persistent Volume Claim(PVC)
persistent Volume(PV)
(lifecycle) hook
- PostStart
- PreStop
Hook Handlers: Exec and HTTP
1 | lifecycle: |
bootstram command
sh -c allows running multiple commands in a single shell
exec ensures the mount process becomes the main process of the container
e.g.
1 | containers: |
Secret
create
1
kubectl create secret generic user --from-file=./username.txt
check
1
kubectl get secrets
ConfigMap
create
1
kubectl create configmap ui-config --from-file=example/ui.properties
delete
1
kubectl delete configmap <name> -n <namespace>
get yaml
1
kubectl get configmaps ui-config -o yaml
CronJob
infra container (pause container)
在 Kubernetes 项目里,Pod 的实现需要使用一个中间容器,这个容器叫作 Infra 容器。在这个 Pod 中,Infra 容器永远都是第一个被创建的容器,而其他用户定义的容器,则通过 Join Network Namespace 的方式,与 Infra 容器关联在一起。
在 Kubernetes 项目里,Infra 容器一定要占用极少的资源,所以它使用的是一个非常特殊的镜像,叫作:
k8s.gcr.io/pause。这个镜像是一个用汇编语言编写的、永远处于“暂停”状态的容器,解压后的大小也只有 100~200 KB 左右。
- infra container 负责运行网络和 IPC 命名空间的初始化任务,以及为 Pod 中的其他容器提供共享的网络和 IPC (Inter-Process Communication)环境
1 | Maintains pod network namespace and keeps pod alive |
stragety
ImagePullPolicy
1
Always Never IfNotPresent
Lifecycle
1
postStart preStop
restartPolicy
1
2
3Always:在任何情况下,只要容器不在运行状态,就自动重启容器;
OnFailure: 只在容器异常时才自动重启容器;
Never: 从来不重启容器。PodPreset
1
PodPreset 里定义的内容,只会在 Pod API 对象被创建之前追加在这个对象本身上,而不会影响任何 Pod 的控制器的定义
Status
1
pending running succeeded failed upknown
Volume
所谓容器的 Volume,其实就是将一个宿主机上的目录,跟一个容器里的目录绑定挂载在了一起
所谓的“持久化 Volume”,指的就是这个宿主机上的目录,具备“持久性”。即这个目录里面的内容,既不会因为容器的删除而被清理掉,也不会跟当前的宿主机绑定。
“持久化”宿主机目录的过程,可以形象地称为“两阶段处理”
- 第一阶段 Attach:虚拟机挂载远程磁盘的操作
- 第二阶段 Mount:将磁盘设备格式化并挂载到 Volume 宿主机目录的操作
StorageClass
StorageClass defines the provisioner and parameters for dynamic storage provisioning.
a StorageClass is a global resource and is not limited to a specific namespace. It can be used by any pod across all namespaces in the cluster.
定义
1
2第一,PV 的属性。比如,存储类型、Volume 的大小等等。
第二,创建这种 PV 需要用到的存储插件。比如,Ceph 等等。充当 PV 的模板。并且,只有同属于一个 StorageClass 的 PV 和 PVC,才可以绑定在一起
PVC
PersistentVolumeClaim (PVC) requests storage and can specify a StorageClass to trigger the dynamic creation of a PersistentVolume.
The PVC size controls how much storage is made available to a pod, and all of that storage is accessible to the pod.
There is no way to further subdivide the storage provided to a pod by the PVC. Once the PVC is created, all storage allocated by it is available to the pod.
- PVCs are namespace-scoped: PVCs are created within a specific namespace and request storage from available PVs or a StorageClass.
PV
PersistentVolume (PV) is either dynamically created based on the PVC’s request or manually created and bound to a PVC.
so PV cannot directly use a StorageClass for dynamic provisioning util a PVC to trigger the provisioning process.
in other words, PVs are either statically provisioned (manually created) or dynamically provisioned via a PVC.
so Even if you manually create a PV, it won’t be useful until a PVC binds to it.
- PVs are global resources: They can be used across namespaces.
provision
- static provisioning, the relationship between a PersistentVolume (PV) and a PersistentVolumeClaim (PVC) is strictly 1:1 at any given time.
RBAC
Role-Based Access Control
reference Kubernetes RBAC
Operator
Operator 的工作原理,实际上是利用了 Kubernetes 的自定义 API 资源(custom resource definitions (CRDs)),来描述我们想要部署的“有状态应用”;然后在自定义控制器里,根据自定义 API 对象的变化,来完成具体的部署和运维工作
In other words, Operators are software extensions that use custom resources to manage applications and their components
controller
Controller is just some logic about something that it is supposed to be managed and is usually visualised as an observe and adjust loop.
Observe the current state, compare it to the desired state and adjust the state
custom resource(CR)
state
The state just holds the information of what the desired state of the resource is and the resource is the thing that you are managing.
Operator vs Deployment
| Feature | Operator | Deployment |
|---|---|---|
| Definition | A Kubernetes Operator automates the lifecycle of an application, handling deployment, upgrades, scaling, and failure recovery. | A Deployment is a Kubernetes object that manages a set of pods with defined scaling and update strategies. |
| Automation Level | High: Operators provide full lifecycle automation. | Basic: Deployments only handle pod management and scaling. |
| Custom Resource (CRD) | Uses Custom Resource Definitions (CRDs) to extend Kubernetes functionality. | Uses built-in resources like Deployment, Service, ReplicaSet. |
| Scaling | Can provide intelligent auto-scaling based on workload behavior. | Relies on Horizontal Pod Autoscaler (HPA) or manual scaling. |
| Upgrade Handling | Handles zero-downtime upgrades with rollback capabilities. | Uses RollingUpdate or Recreate strategies. |
| Failure Recovery | Can detect failures and take automated corrective actions. | Relies on Kubernetes itself to restart pods. |
| Complexity | More complex, requires coding and maintaining an Operator. | Simpler, uses YAML definitions. |
Operators use Deployments internally to manage application workloads.
A Deployment only manages pods, but an Operator enhances this by managing the entire application lifecycle.
Operators create, update, and delete Deployments dynamically based on defined logic.
CNI
TBD
TIPS
过去很多的集群管理项目(比如 Yarn、Mesos,以及 Swarm)所擅长的,都是把一个容器,按照某种规则,放置在某个最佳节点上运行起来。这种功能,我们称为“调度”。
而 Kubernetes 项目所擅长的,是按照用户的意愿和整个系统的规则,完全自动化地处理好容器之间的各种关系。这种功能,就是:编排。
更新pod的image
1
2
3
4
5method 1, config yaml
imagePullPolicy: Always
method 2, manually delete pod
kubectl delete pod <pod-name>
FAQ
node pod cidr not assigned
- Step 1
1 | master node |
kube-controller-manager.yaml info
1 | ... |
- step2
1 | sudo systemctl restart kubelet |
failed to set bridge addr: “cni0“ already has an IP address different from xxx
- check
1 | node1 |
cni0与flannel应该需要在一个网段里
- delete
cni0
1 | node1/node2/node3 |
- restore
coredns
1 | error info |
delete coredns, k8s system will auto recreate it
1 | kubectl get po -o wide -n kube-system |
namespace Terminating
1 | step1: check resource in namespace |
pod Terminating
1 | kubectl delete pod <pod-name> --grace-period=0 --force --namespace <namespace> |
flannel with kubeadm init
after install flannel , KubeletNotReady container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: cni plugin not initialized
all nodes is NotReady
1 | reboot all nodes |