A BLOB can be 65535 bytes (64 KB) maximum. If you need more consider using: a MEDIUMBLOB for 16777215 bytes (16 MB) a LONGBLOB for 4294967295 bytes (4 GB).
DML statements are SQL statements that manipulate data. DML stands for Data Manipulation Language. The SQL statements that are in the DML class are INSERT, UPDATE and DELETE. Some people also lump the SELECT statement in the DML classification.
Data Definition Languages (DDL) are used to define the database structure. Any CREATE, DROP and ALTER commands are examples of DDL SQL statements.
设置远程登录
mysql 8版本设置可用root远程访问服务
1 2 3 4 5
CREATE USER 'root'@'%' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
Bash:Bourne-Again SHell Bash is a command language interpreter.
conclusion
Do not be afraid to break things as that is perfectly normal. Troubleshooting and fixing code is perhaps the best booster for you to enhance your understanding of bash scripting and to improve your ability.
Java 8 introduces the “Default Method” or (Defender methods) feature, which allows the developer to add new methods to the interfaces without breaking their existing implementation. It provides the flexibility to allow interface to define implementation which will use as the default in a situation where a concrete class fails to provide an implementation for that method.
Functional Interfaces and Lambda Expressions
Functional Interfaces
Being object oriented is not bad, but it brings a lot of verbosity to the program. Java 8 Functional Interfaces and Lambda Expressions help us in writing smaller and cleaner code by removing a lot of boiler-plate code.
An interface with exactly one abstract method is called Functional Interface. @FunctionalInterface annotation is added so that we can mark an interface as functional interface.
Some of the useful java 8 functional interfaces are Consumer, Supplier, Function and Predicate.
Lambda Expression
Objects are the base of java programming language and we can never have a function without an Object, that’s why Java language provide support for using lambda expressions only with functional interfaces.
Lambda Expressions syntax is (argument) -> (body).
Java Stream API for Bulk Data Operations on Collections
Session simply means a particular interval of time. Session Tracking is a way to maintain state (data) of an user. It is also known as session management in servlet.
HTTP is stateless that means each request is considered as the new request. It is shown in the figure given below:
There are four techniques used in Session tracking:
Cookies
Hidden Form Field
URL Rewriting
HttpSession
cookie
A cookie is a small piece of information that is persisted between the multiple client requests. A cookie has a name, a single value, and optional attributes such as a comment, path and domain qualifiers, a maximum age, and a version number.
how cookie work
type of cookie
Non-persistent cookie
It is valid for single session only. It is removed each time when user closes the browser.
Persistent cookie
It is valid for multiple session . It is not removed each time when user closes the browser. It is removed only if user logout or signout.
Advantage
Simplest technique of maintaining the state.
Cookies are maintained at client side.
Disadvantage
It will not work if cookie is disabled from the browser.
Only textual information can be set in Cookie object.
HttpSession Interface
An object of HttpSession can be used to perform two tasks:
bind objects
view and manipulate information about a session, such as the session identifier, creation time, and last accessed time.
HTTP is the communication protocol between server and client. HTTP runs on top of TCP/IP communication protocol.
Port numbers 0 to 1023 are reserved ports for well known services, for example 80 for HTTP, 443 for HTTPS, 21 for FTP etc.
Java Servlet and JSPs are server side technologies to extend the capability of web servers by providing support for dynamic response and data persistence.
Web Container
When web container gets the request and if it’s for servlet then container creates two Objects HTTPServletRequest and HTTPServletResponse. Then it finds the correct servlet based on the URL and creates a thread for the request. Then it invokes the servlet service() method and based on the HTTP method service() method invokes doGet() or doPost() methods. Servlet methods generate the dynamic page and write it to response. Once servlet thread is complete, container converts the response to HTTP response and send it back to client.
Some of the important work done by web container are:
Communication Support – Container provides easy way of communication between web server and the servlets and JSPs. Because of container, we don’t need to build a server socket to listen for any request from web server, parse the request and generate response. All these important and complex tasks are done by container and all we need to focus is on our business logic for our applications.
Lifecycle and Resource Management – Container takes care of managing the life cycle of servlet. Container takes care of loading the servlets into memory, initializing servlets, invoking servlet methods and destroying them. Container also provides utility like JNDI for resource pooling and management.
Multithreading Support – Container creates new thread for every request to the servlet and when it’s processed the thread dies. So servlets are not initialized for each request and saves time and memory.
JSP Support – JSPs doesn’t look like normal java classes and web container provides support for JSP. Every JSP in the application is compiled by container and converted to Servlet and then container manages them like other servlets.
Miscellaneous Task – Web container manages the resource pool, does memory optimizations, run garbage collector, provides security configurations, support for multiple applications, hot deployment and several other tasks behind the scene that makes our life easier.
Java Web Applications are packaged as Web Archive (WAR) and it has a defined structure.
Servlet
Servlet API Hierarchy
Session Management
What is a Session?
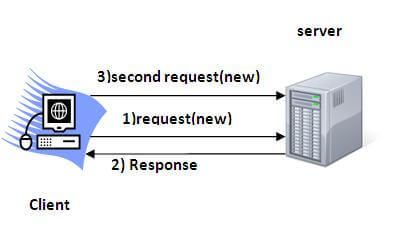
HTTP protocol and Web Servers are stateless, what it means is that for web server every request is a new request to process and they can’t identify if it’s coming from client that has been sending request previously.
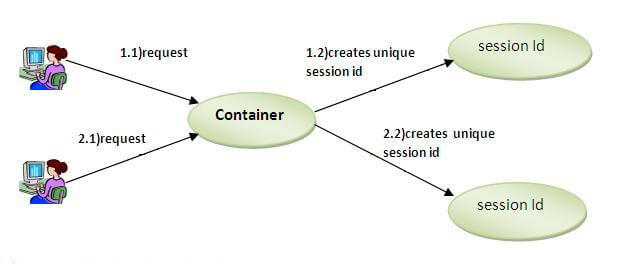
Session is a conversional state between client and server and it can consists of multiple request and response between client and server. Since HTTP and Web Server both are stateless, the only way to maintain a session is when some unique information about the session (session id) is passed between server and client in every request and response.
JSESSIONID Cookie
When we use HttpServletRequest getSession() method and it creates a new request, it creates the new HttpSession object and also add a Cookie to the response object with name JSESSIONID and value as session id. This cookie is used to identify the HttpSession object in further requests from client. If the cookies are disabled at client side and we are using URL rewriting then this method uses the jsessionid value from the request URL to find the corresponding session. JSESSIONID cookie is used for session tracking, so we should not use it for our application purposes to avoid any session related issues.
When a JSP resource is used, container automatically creates a session for it, so we can’t check if session is null to make sure if user has come through login page, so we are using session attribute to validate request.
As we saw in last section that we can manage a session with HttpSession but if we disable the cookies in browser, it won’t work because server will not receive the JSESSIONID cookie from client.
Cookie Basics
a cookie is a small piece of data stored on the client-side which servers use when communicating with clients.They’re used to identify a client when sending a subsequent request. They can also be used for passing some data from one servlet to another.